Thẻ meta robots là gì? Cách cài đặt, kiểm tra và tránh lỗi mất index
Thẻ meta robots là gì và dùng để làm gì?
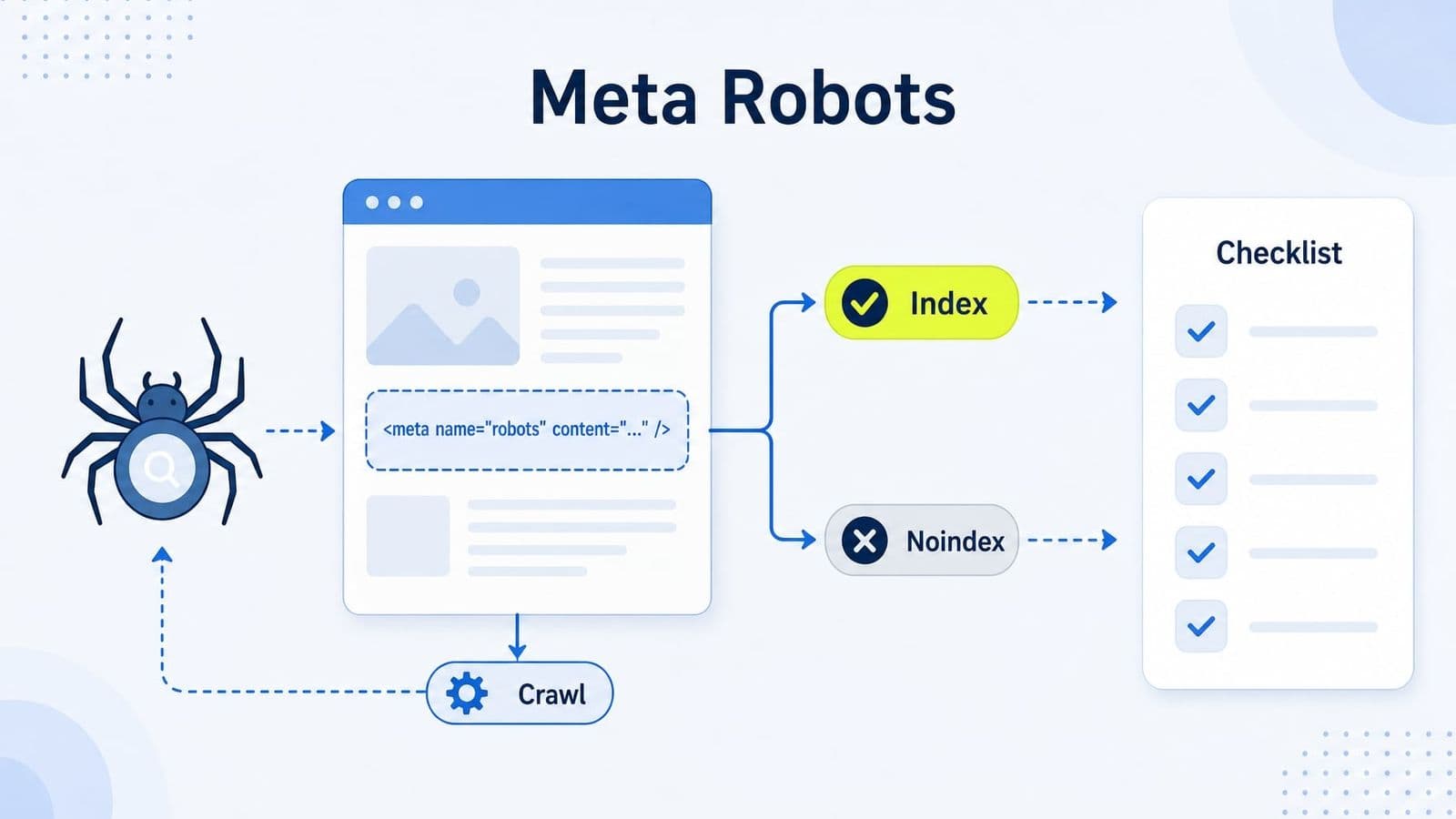
Thẻ meta robots là một thẻ HTML nằm trong phần <head>, dùng để hướng dẫn bot tìm kiếm cách xử lý một trang cụ thể về index, follow và cách hiển thị snippet. Khác với robots.txt, đây là công cụ kiểm soát ở cấp trang chứ không áp dụng cho toàn site.
Về bản chất, thẻ meta robots là một chỉ thị điều hướng (directive) giúp bạn ra lệnh cho Googlebot biết liệu một URL có nên được lập chỉ mục hay không, có nên theo liên kết trên trang hay không, và trong một số trường hợp, nội dung được phép hiển thị trên kết quả tìm kiếm đến mức nào.
Điểm cần phân biệt đầu tiên là crawl (bot truy cập và đọc trang) không đồng nghĩa với index (công cụ tìm kiếm đưa trang vào hệ thống lập chỉ mục). Nhiều website gặp lỗi trong SEO technical không phải vì nội dung kém, mà vì tín hiệu index được đặt sai. Một ví dụ rất phổ biến là sau khi sửa template, toàn bộ nhóm bài blog bị chèn noindex, khiến traffic organic giảm mạnh dù nội dung không thay đổi.
Một giới hạn quan trọng: bot cần truy cập được trang thì mới đọc được index control tag này. Nếu URL bị chặn hoàn toàn bởi robots.txt, công cụ tìm kiếm có thể không nhìn thấy chỉ thị noindex bên trong trang.
Meta robots kiểm soát gì?
- Index / noindex: Có hoặc không đưa trang vào kết quả tìm kiếm.
- Follow / nofollow: Có hoặc không theo các liên kết trên trang.
- Snippet controls: Kiểm soát mô tả, ảnh preview, video preview.
- Page-level control: Áp dụng cho từng URL riêng lẻ.
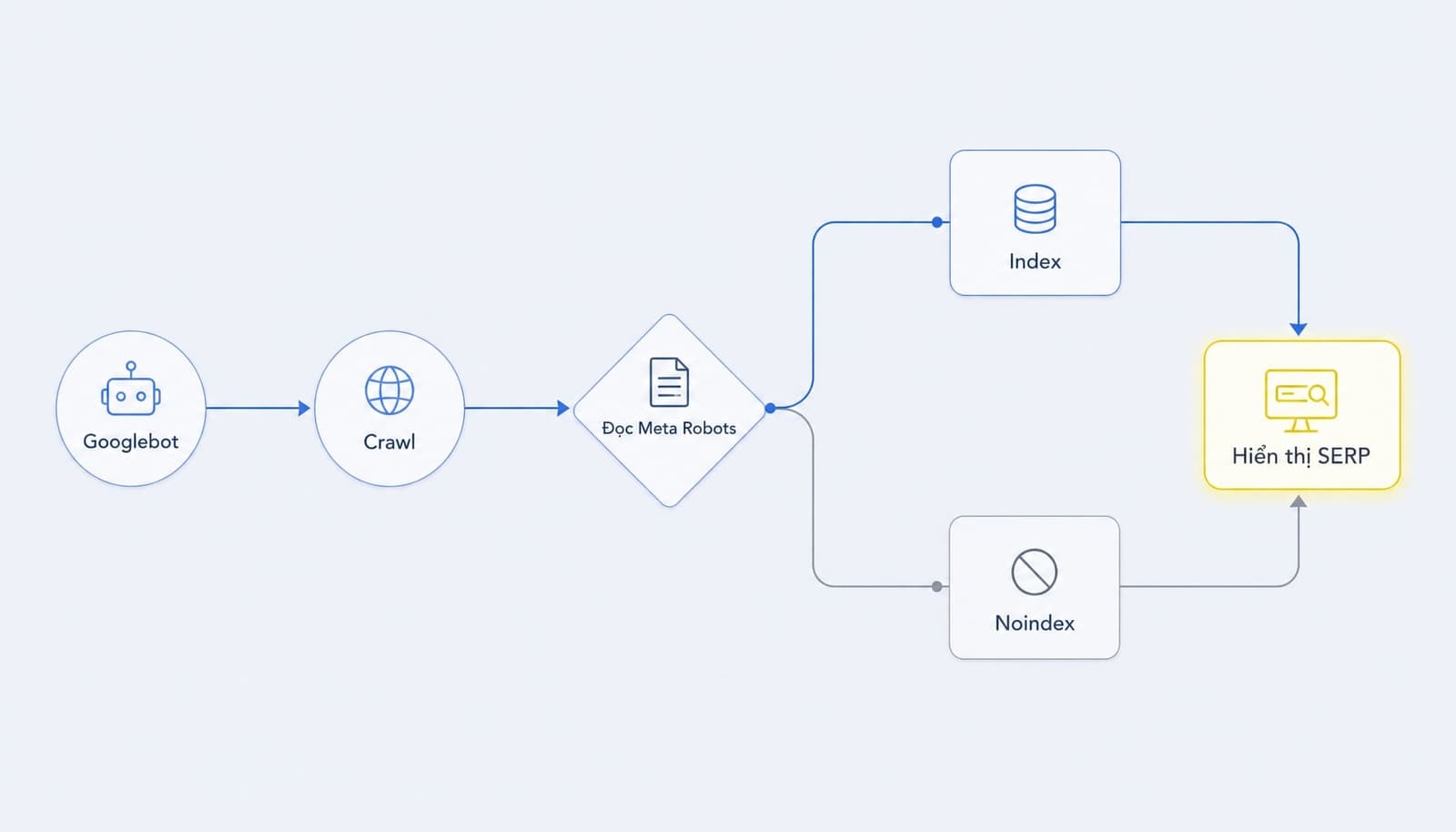
Thẻ meta robots hoạt động ở đâu?
- Thẻ này nằm trong phần HTML head của từng trang.
- Googlebot đọc chỉ thị khi truy cập và crawl URL đó.
- Nếu URL bị chặn hoàn toàn bởi robots.txt, bot có thể không thấy chỉ thị bên trong trang.
- Chỉ thị áp dụng cho từng URL, không phải toàn bộ website.
Cú pháp cơ bản của thẻ meta robots
<meta name="robots" content="noindex, nofollow">
Trong cú pháp meta robots này:
name="robots"nghĩa là chỉ thị áp dụng cho các bot nói chung.contentchứa các directive như noindex, nofollow.- Nếu muốn nhắm riêng một bot, có thể dùng
name="googlebot"thay cho name="robots". - Không nên để nhiều thẻ robots mâu thuẫn nhau trên cùng một trang, ví dụ một thẻ
indexvà một thẻnoindex.
Các Directive quan trọng trong thẻ meta robots
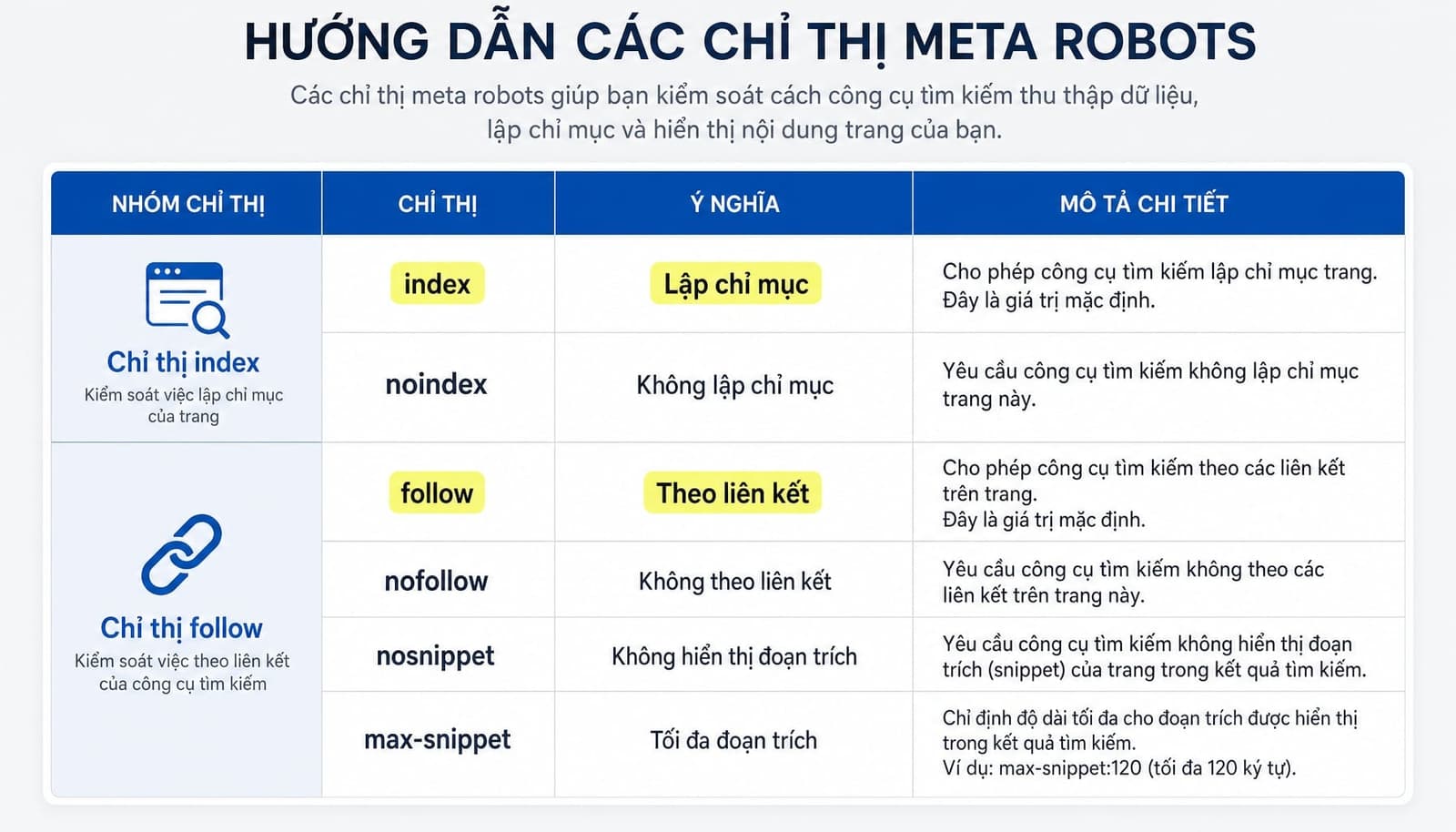
Nếu chỉ cần nắm phần cốt lõi, bạn nên hiểu 6 directive sau trước:
indexnoindexfollownofollownosnippetmax-snippet
Đây là nhóm chỉ thị được dùng thường xuyên nhất khi quản lý index và cách nội dung xuất hiện trên Google. Trong thực tế audit, lỗi không nằm ở việc “thiếu quá nhiều directive”, mà thường nằm ở việc dùng sai noindex hoặc copy checklist SEO cũ mà không hiểu ngữ cảnh.
Nhóm Directive phổ biến nhất
indexnoindexfollownofollownone
Nếu bạn không khai báo bất kỳ chỉ thị nào, Google sẽ mặc định hiểu là index và follow.
Directive | Ý nghĩa |
|---|---|
| Cho phép trang được lập chỉ mục. |
| Không đưa trang vào kết quả tìm kiếm. |
| Bot có thể theo các liên kết trên trang. |
| Bot không theo các liên kết trên trang. |
| Tương đương |
Với phần lớn website doanh nghiệp, noindex là chỉ thị quan trọng nhất vì nó ảnh hưởng trực tiếp đến việc URL có xuất hiện trên Google hay không. Ví dụ: Trang cảm ơn sau khi điền form, trang đăng nhập hoặc trang kết quả tìm kiếm nội bộ thường không cần phải lập chỉ mục (index).
Cần hiểu đúng về nofollow: Đây không phải là chiến lược tối ưu internal link mặc định. Nó chỉ phù hợp trong một số tình huống cụ thể. Dùng nofollow sai mục tiêu có thể làm hệ thống liên kết nội bộ kém hiệu quả hơn.
Nhóm kiểm soát Snippet và hiển thị trên SERP
Các directive dưới đây kiểm soát cách nội dung được trình bày trên trang kết quả tìm kiếm, chứ không thay thế noindex:
nosnippet: Không hiển thị đoạn mô tả văn bản hoặc video preview.max-snippet: Giới hạn số ký tự của snippet.max-image-preview: Giới hạn kích thước ảnh preview.max-video-preview: Giới hạn thời lượng video preview.notranslate: Không đề xuất bản dịch trên kết quả tìm kiếm.
Một điểm mới cần lưu ý: Theo tài liệu Google cập nhật gần đây, nosnippet và max-snippet còn ảnh hưởng đến cách nội dung được dùng trong một số tính năng tìm kiếm có AI. Tuy nhiên, ở góc độ triển khai phổ thông, bạn chỉ nên dùng nhóm này khi có nhu cầu kiểm soát hiển thị thực sự, không phải như một thay thế cho chặn index.Nhóm Directive theo ngữ cảnh đặc biệt
Một số directive có giá trị nhưng không phải website nào cũng cần:
noimageindex: Không index hình ảnh nằm trên trang.unavailable_after: Ngừng hiển thị trang sau một mốc thời gian cụ thể.indexifembedded: Cho phép nội dung được index nếu được nhúng trong trang khác.
Đa số website doanh nghiệp phổ thông ít cần nhóm này. Chỉ nên dùng khi bạn có mục tiêu rõ, ví dụ landing page sự kiện hết hạn, hoặc nội dung được nhúng qua iframe.
Những Directive dễ gây hiểu lầm hoặc đã lỗi thời
Mặc dù các chỉ thị như noarchive và nositelinkssearchbox vẫn được Google hỗ trợ, chúng thường ít được ưu tiên trong các chiến lược SEO hiện đại so với các chỉ thị quan trọng hơn như noindex và nofollow. Bạn không nên copy danh sách directive cũ từ các bài SEO lỗi thời mà không đối chiếu lại tài liệu Google mới.
Phân biệt meta robots, robots.txt và X-Robots-Tag
Ba công cụ này thường bị gom chung, nhưng chúng phục vụ ba mục tiêu khác nhau. Nếu hiểu sai, bạn rất dễ rơi vào tình huống URL bị chặn crawl nhưng vẫn xuất hiện trên Google dưới dạng không đầy đủ.
Điểm cần nhớ: Robots.txt chủ yếu liên quan đến crawlability (khả năng bot truy cập), còn meta robots và X-Robots-Tag liên quan nhiều hơn đến indexing và cách tài nguyên được phục vụ trên kết quả tìm kiếm.
Công cụ | Mục tiêu chính | Vị trí áp dụng | Hỗ trợ deindex / non-HTML |
|---|---|---|---|
Meta robots | Kiểm soát index, follow, snippet ở cấp trang. | Trong HTML của từng URL. | Deindex HTML: Có /Non-HTML: Không. |
robots.txt | Hướng dẫn bot có nên crawl một khu vực nào đó hay không. | File gốc toàn site. | Deindex: Không nên dùng / Non-HTML: Không trực tiếp. |
X-Robots-Tag | Kiểm soát index qua HTTP header. | Header phản hồi của URL/tài nguyên. | Deindex: Có /Non-HTML: Có. |
Ví dụ thực tế:
- Muốn noindex trang cảm ơn sau form: Dùng meta robots.
- Muốn chặn crawl thư mục chứa tài nguyên không cần bot truy cập: Dùng robots.txt.
- Muốn noindex PDF catalogue hoặc tài liệu tải về: Dùng X-Robots-Tag.
Nếu mục tiêu là deindex, bạn đừng chỉ dùng robots.txt. Đây là lỗi rất phổ biến trong technical audit. Khi bot không được crawl, nó có thể không đọc được noindex. URL vẫn có thể xuất hiện nếu còn tín hiệu từ liên kết ngoài, sitemap cũ hoặc nguồn tham chiếu khác.

Cách cài đặt thẻ meta robots đơn giản và đúng ngữ cảnh
Nếu mục tiêu của bạn là triển khai nhanh nhưng không sai bản chất, hãy đi theo 4 bước sau:
- Xác định URL nào cần index hoặc noindex.
- Chọn đúng công cụ: meta robots, robots.txt hay X-Robots-Tag.
- Thêm chỉ thị đúng cú pháp.
- Kiểm tra lại bằng công cụ thay vì đoán.
Đây là phần quan trọng vì nhiều người dừng ở bước “đã thêm thẻ”, nhưng không verify sau khi triển khai. Trong thực tế, lỗi trùng lặp thẻ, cache cũ hoặc plugin ghi đè setting xảy ra khá thường xuyên.
Cách thêm vào HTML thủ công
Bạn có thể thêm trực tiếp trong phần HTML head của trang:
- Mẫu này thường dùng khi bạn muốn URL không xuất hiện trên Google nhưng vẫn cho bot đi theo các liên kết trên trang:
<meta name="robots" content="noindex, follow">
- Mẫu này phù hợp cho các URL không có giá trị SEO hoặc điều hướng, ví dụ một số trang nội bộ tạm thời:
<meta name="robots" content="noindex, nofollow">
Lưu ý khi thêm thủ công:
- Chèn đúng trong HTML head.
- Không để nhiều thẻ meta name="robots" trùng lặp.
- Không tạo directive mâu thuẫn giữa template, plugin và code hard-code.
Cách cài trên WordPress bằng plugin SEO
Với WordPress, cách cài đặt thẻ meta robots đơn giản nhất là dùng plugin như Yoast SEO hoặc Rank Math.
Yoast SEO
- Mở trang hoặc bài viết cần chỉnh.
- Vào phần cài đặt SEO nâng cao.
- Chọn có hoặc không cho phép công cụ tìm kiếm hiển thị URL này.
- Lưu và kiểm tra lại source.
Rank Math
- Mở bài viết hoặc trang.
- Vào tab Advanced.
- Chọn
IndexhoặcNoindex - Bật/tắt follow nếu cần.
- Cập nhật bài viết.
Các khu vực hay bị noindex WordPress nhầm mà bạn cần chú ý:
- Category.
- Tag.
- Media attachment noindex.
- Search page.
- Một số post type do plugin tạo ra.
Sau khi update theme hoặc plugin, bạn nên kiểm tra lại. Nhiều website mất traffic không phải do thuật toán, mà do setting bị ghi đè sau khi bảo trì.
Những lỗi phổ biến khi dùng thẻ meta robots khiến website mất index hoặc giảm traffic
Phần lớn lỗi meta robots không đến từ một directive quá phức tạp, mà đến từ việc đặt đúng cú pháp nhưng sai ngữ cảnh. Trong technical SEO audit, đây là nhóm lỗi có thể gây tác động trực tiếp đến organic traffic và lead inbound.
Lỗi 1: Nhầm giữa chặn Crawl và chặn Index
Nguyên nhân
- Dùng
Disallowtrongrobots.txtrồi nghĩ rằng URL sẽ biến mất khỏi Google - Chặn crawl trước khi bot kịp đọc
noindex
Hậu quả
- Bot không truy cập được trang nên có thể không thấy
noindex - URL vẫn có thể xuất hiện từ tín hiệu liên kết hoặc dữ liệu cũ
- Gây hiểu nhầm rằng “đã xử lý xong” nhưng thực tế chưa deindex
Cách xử lý
- Nếu mục tiêu là deindex, ưu tiên meta robots
noindexhoặc X-Robots-Tag phù hợp. - Không nên trộn lẫn robots.txt và noindex theo cách làm bot không đọc được chỉ thị.
- Kiểm tra trạng thái lại trong Search Console.
Lỗi 2: Đẩy Staging Noindex lên Production
Đây là lỗi rất hay gặp sau redesign, migrate hoặc thay theme.
Nguyên nhân
- Website staging noindex để tránh index thử nghiệm.
- Khi deploy sang production, đội triển khai quên gỡ chỉ thị.
Hậu quả
- Có thể ảnh hưởng toàn site nếu noindex nằm ở template chung.
- Traffic giảm đồng loạt, đặc biệt ở nhóm trang quan trọng.
Cách xử lý
- Kiểm tra template, source code, plugin và setting CMS.
- Dùng Search Console để xác minh sau khi sửa.
- Lưu ý: gỡ
noindexkhông có nghĩa là phục hồi ngay. Bot cần crawl lại trước khi trạng thái index cập nhật.
Lỗi 3: Dùng Directive sai mục tiêu
Không phải mọi URL traffic thấp đều nên noindex.
Nguyên nhân
- Dùng
nofollownhư một chiến lược internal link mặc định. - Noindex hàng loạt các trang “mỏng” mà chưa xét giá trị kinh doanh của URL.
- Loại URL khỏi sitemap quá sớm trước khi deindex hoàn tất.
Hậu quả
- Mất các trang hỗ trợ funnel, điều hướng hoặc chuyển đổi.
- Tín hiệu nội bộ bị rối.
- Khó theo dõi trạng thái thật của URL.
Cách xử lý
- Đánh giá từng URL theo mục tiêu tìm kiếm, điều hướng và chuyển đổi.
- Giữ URL trong sitemap đến khi deindex hoàn tất.
- Không áp dụng máy móc một checklist cũ cho toàn site.
Checklist kiểm tra sau khi cài thẻ meta robots
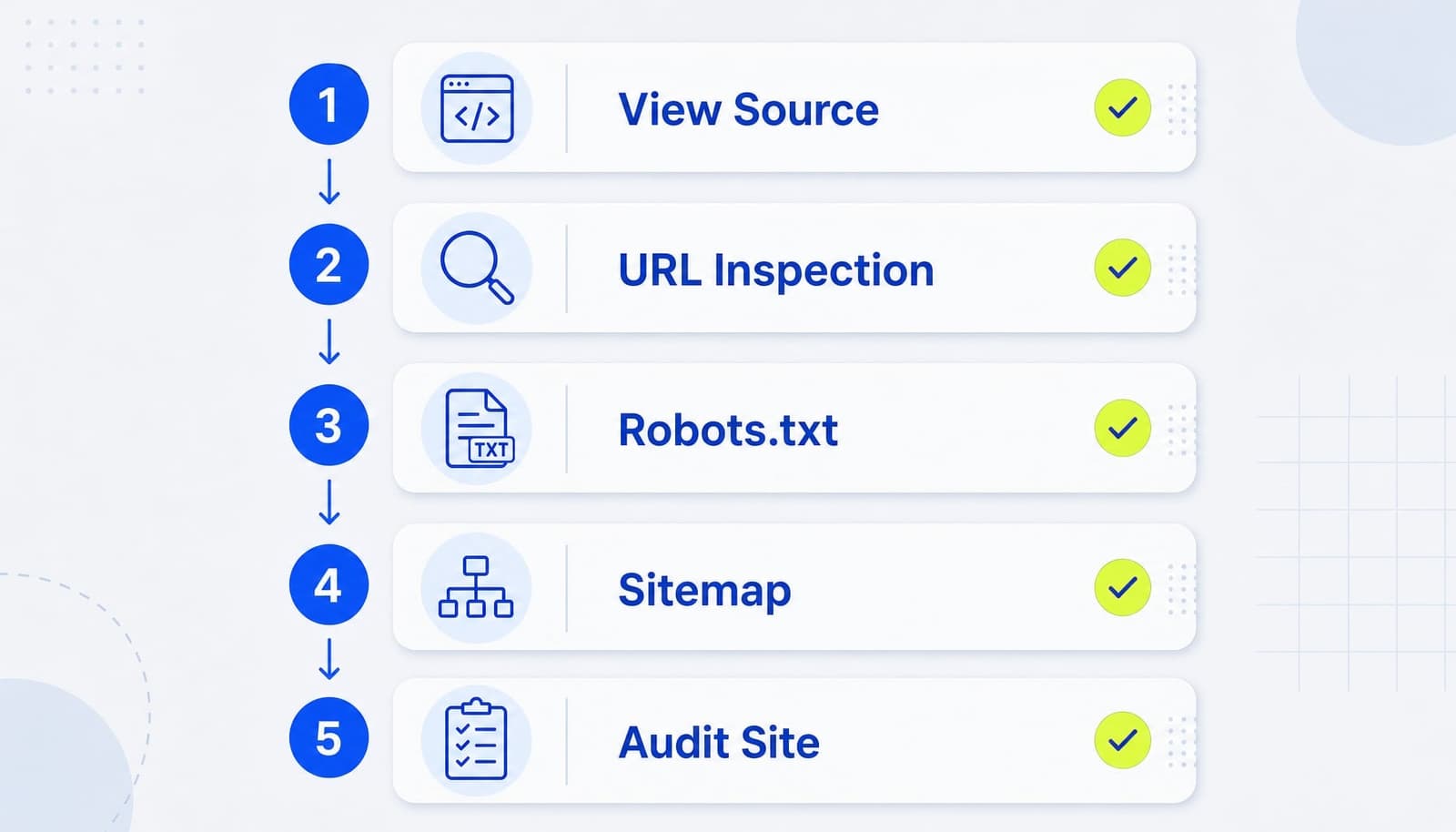
Cách an toàn nhất là kiểm tra theo đúng thứ tự, từ source code đến trạng thái bot nhìn thấy. Với website lớn, bạn nên xem đây là một bước bắt buộc của quy trình triển khai.
- Mở
View Sourceđể kiểm tra thẻ có xuất hiện đúng không bằng cách tìmmeta name="robots"và xem directive có đúng ý định hay bị plugin ghi đè. - Dùng
URL Inspectiontrong Search Console là cách tốt để xem Google nhìn thấy URL thế nào, có index được không và có phát hiệnnoindexhay không. - Kiểm tra
robots.txtđể đảm bảo bạn không vô tình chặn crawl của URL đang cần bot đọc chỉ thị. - Soát
sitemapvà internal link: Nếu một URL đang cần deindex, hãy kiểm tra xem nó còn được đẩy mạnh trong sitemap hoặc liên kết nội bộ hay không. - Crawl toàn site bằng công cụ audit: Với site lớn, nên crawl site bằng công cụ audit để phát hiện noindex diện rộng, thẻ trùng lặp hoặc nhóm URL bị lỗi template.
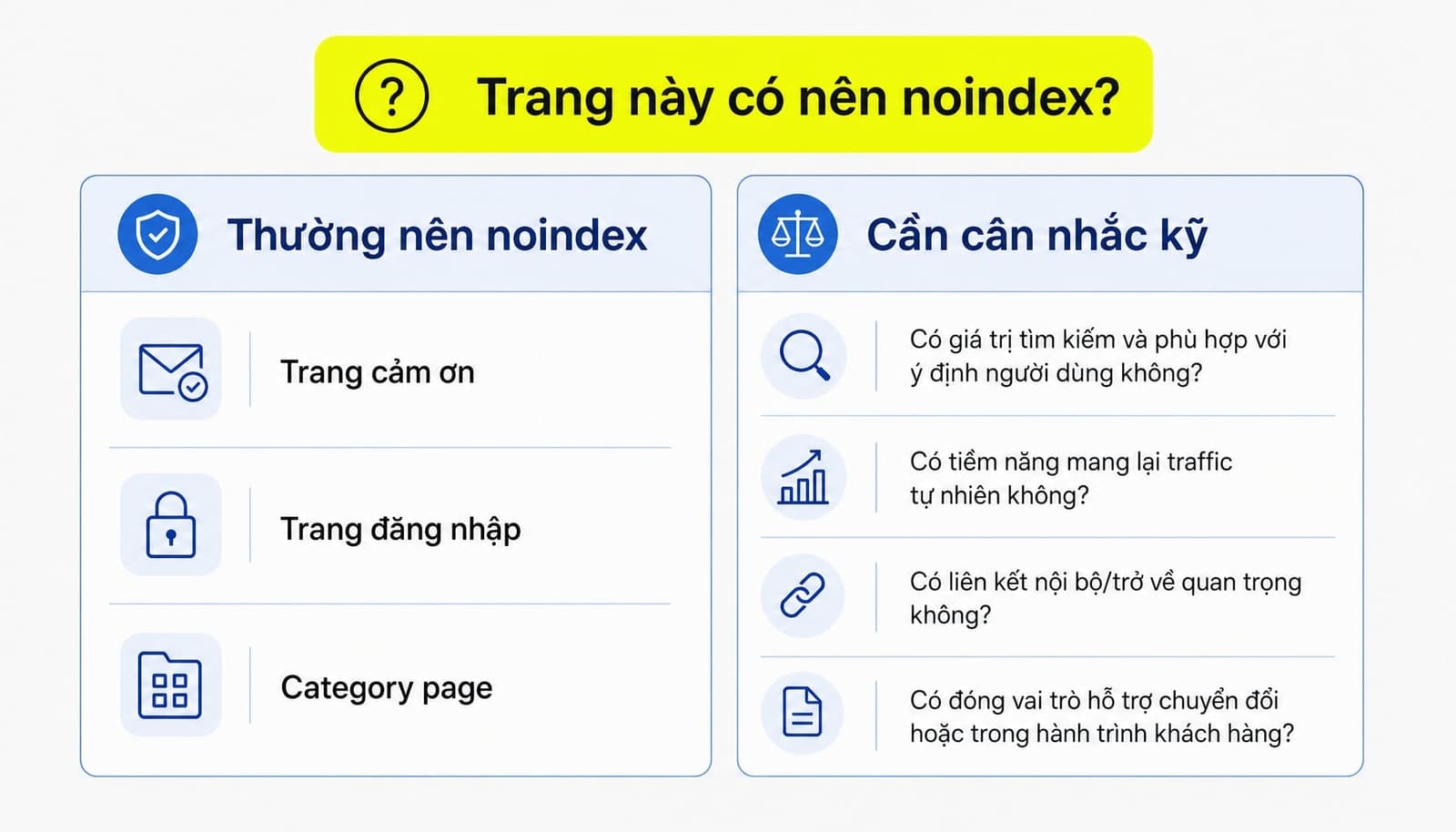
Ví dụ thực tế: Những trang nào nên noindex và những trang nào không nên?
Có những nhóm trang nên noindex khá rõ ràng. Nhưng cũng có nhiều URL không thể quyết định theo kiểu “cứ traffic thấp là noindex”. Với website doanh nghiệp, quyết định đúng phải dựa trên giá trị tìm kiếm, điều hướng và chuyển đổi.
Thường nên noindex | Cần cân nhắc kỹ |
|---|---|
Trang cảm ơn sau khi điển form. | Category page. |
Trang login/admin page. | Landing page chạy ads dài hạn. |
Kết quả tìm kiếm nội bộ. | Blog hỗ trợ funnel. |
Staging hoặc môi trường test. | Tài nguyên hữu ích như guide, PDF SEO-friendly. |
Ví dụ với website doanh nghiệp:
- Trang cảm ơn sau đăng ký webinar thường nên noindex.
- Trang đăng nhập nội bộ không cần lên Google.
- Nhưng category page có thể có giá trị điều hướng và gom nhu cầu tìm kiếm.
- Một landing page chạy ads dài hạn đôi khi vẫn đáng được index nếu có giá trị thông tin và chuyển đổi.
Câu hỏi quan trọng nhất là: URL này có giá trị tìm kiếm, điều hướng hoặc chuyển đổi hay không?
Câu hỏi thường gặp
Thẻ meta robots là gì và nó kiểm soát những yếu tố nào?
Thẻ meta robots là một đoạn mã HTML đặt trong phần <head> của trang web, đóng vai trò hướng dẫn trình thu thập thông tin (crawlers) về cách xử lý nội dung trang đó. Thẻ này kiểm soát chủ yếu việc lập chỉ mục (index), theo dõi liên kết (follow) và cách hiển thị nội dung trang trên kết quả tìm kiếm (snippet).
Tại sao không nên dùng robots.txt để chặn Google index một trang web?
Tệp robots.txt chỉ quản lý quyền truy cập (crawl) của bot, không đảm bảo việc deindex (xóa khỏi chỉ mục). Nếu bạn chặn crawl trong robots.txt, Googlebot không thể đọc được chỉ thị noindex trên trang đó. Kết quả là trang vẫn có thể bị Google lập chỉ mục nếu được liên kết từ các website khác.
Sự khác biệt chính giữa thẻ meta robots và X-Robots-Tag là gì?
Thẻ meta robots là một thẻ HTML nằm trong mã nguồn của trang web, phù hợp cho các tệp HTML. Trong khi đó, X-Robots-Tag là một chỉ thị trong HTTP Header (gửi từ máy chủ), được dùng để kiểm soát việc lập chỉ mục cho các tệp non-HTML như tệp PDF, tài liệu hoặc hình ảnh.
Làm thế nào để kiểm tra thẻ meta robots đã được cài đặt đúng chưa?
Bạn có thể kiểm tra bằng cách:
- Sử dụng tính năng "View Source" trên trình duyệt để tìm thẻ meta.
- Dùng công cụ "URL Inspection" trong Google Search Console để xem Googlebot đang nhận chỉ thị nào.
- Sử dụng các công cụ audit website như Semrush hoặc Ahrefs để quét toàn bộ hệ thống và phát hiện các lỗi thiết lập sai.
Các chỉ thị nosnippet và max-snippet có ảnh hưởng đến AI Overviews không?
Có. Google đã cập nhật tài liệu hướng dẫn, khẳng định các chỉ thị nosnippet và max-snippet hiện nay không chỉ áp dụng cho kết quả tìm kiếm truyền thống mà còn giới hạn việc sử dụng nội dung trang web làm đầu vào trực tiếp cho các tính năng AI Overviews và AI Mode.
Những trang nào trên website thường nên đặt thẻ noindex?
Bạn nên cân nhắc đặt noindex cho các trang không có giá trị tìm kiếm hoặc cần bảo mật, bao gồm: trang cảm ơn sau khi đăng ký, trang kết quả tìm kiếm nội bộ, trang quản trị (admin/login), và các trang staging đang trong quá trình phát triển để tránh bị lập chỉ mục nhầm.
Xem thêm:
- Web Crawler là gì? Cách bot thu thập dữ liệu website cho SEO
- Website không index: Nguyên nhân và cách khắc phục nhanh nhất
- Mobile-First Indexing là gì? Cách tối ưu website chuẩn Google
Kết luận
Thẻ meta robots là công cụ kiểm soát index ở cấp trang, rất hữu ích khi bạn cần quản lý URL nào nên xuất hiện trên Google và URL nào không. Điểm cốt lõi là phải phân biệt rõ vai trò của meta robots, robots.txt và X-Robots-Tag, đồng thời hiểu rằng crawl không đồng nghĩa với index.
Nếu website có dấu hiệu mất index sau khi sửa theme, migrate hoặc cập nhật plugin, hãy tự rà soát ngay theo checklist ở trên trước khi kết luận nguyên nhân nằm ở nội dung hay thuật toán. Trong trường hợp lỗi ảnh hưởng diện rộng, một phiên audit technical SEO sẽ giúp xác định nhanh URL nào đang bị noindex nhầm, chặn crawl sai hoặc xung đột chỉ thị. Liên hệ với đội ngũ chuyên gia SEO On Top qua số điện thoại 0345 60 64 69 hoặc email info@seoon.top nếu quý doanh nghiệp cần hỗ trợ rà soát kỹ thuật và chuẩn hóa tín hiệu index cho toàn website.
.jpg&w=160&q=75)


