Robots.txt là gì? Cách hoạt động, công dụng và tạo file robots.txt an toàn
Robots.txt là gì?
Robots.txt là một file văn bản nằm ở thư mục gốc của website, dùng để hướng dẫn các bot tìm kiếm về khu vực nào được phép hoặc không được phép thu thập dữ liệu. Nó thuộc Robots Exclusion Protocol và chủ yếu kiểm soát việc bot có crawl URL hay không, chứ không phải công cụ bảo mật hay chặn index tuyệt đối.
Hiểu đơn giản, khi một web crawler (trình thu thập dữ liệu web) như Googlebot truy cập website, nó thường kiểm tra file robots.txt trước. Dựa trên các chỉ dẫn trong file, bot sẽ quyết định nên tiếp tục crawl (thu thập dữ liệu) URL nào và bỏ qua URL nào.
Trong audit technical SEO, đây là một trong những file nhỏ nhưng có tác động lớn nhất. Chúng tôi thường gặp trường hợp website chỉ vì một dòng Disallow: / mà bot gần như bỏ qua toàn bộ phần nội dung quan trọng trên môi trường live.
Điểm cần nhớ sớm là: Nếu bạn đang tìm câu trả lời chính xác cho “robots.txt là gì”, thì bản chất của nó là một file điều hướng bot. Nó không phải hàng rào bảo mật, và cũng không đảm bảo một URL sẽ biến mất khỏi Google.
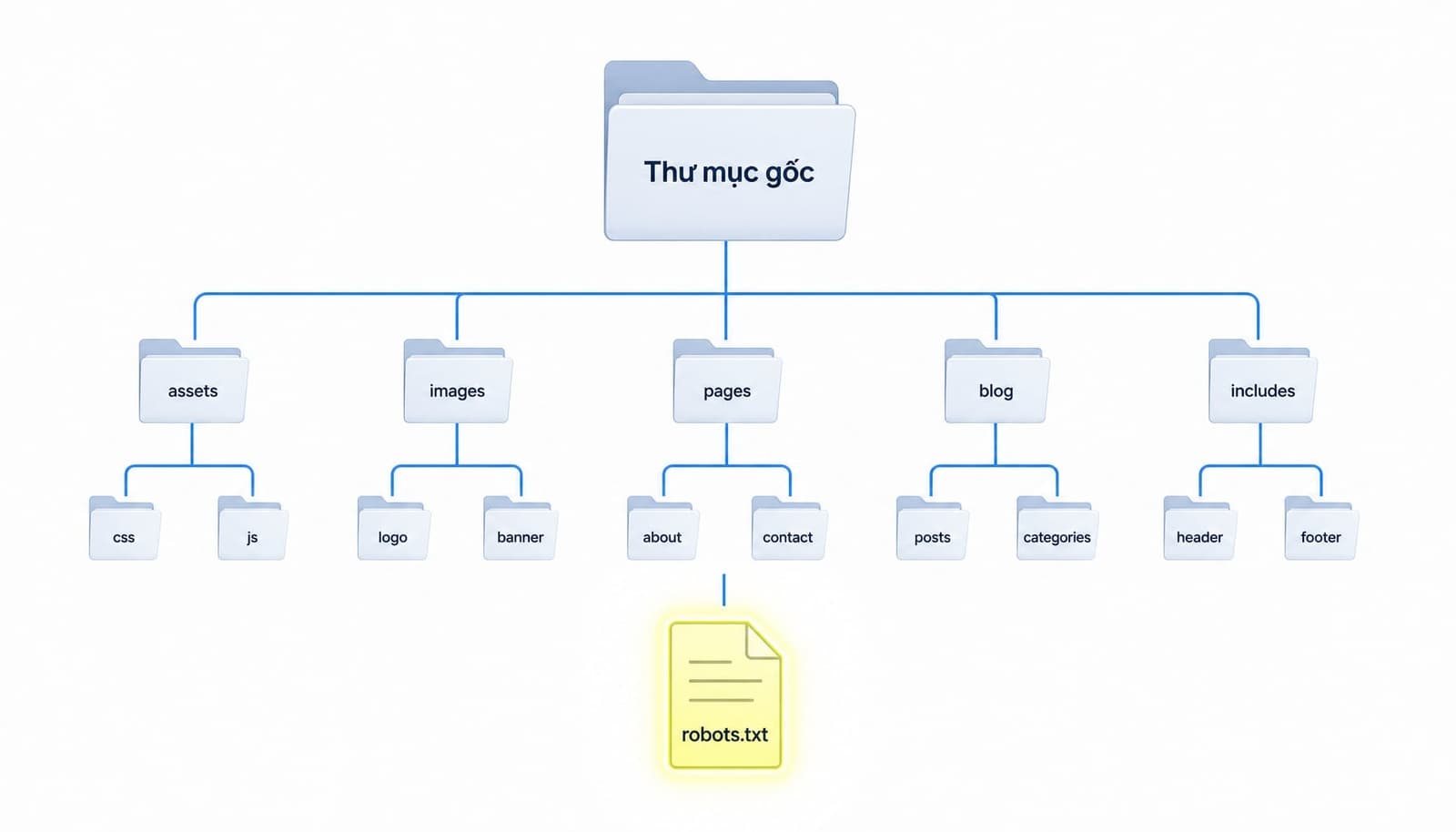
Robots.txt nằm ở đâu trên website?
Robots.txt nằm ở thư mục gốc của website và thường truy cập công khai qua đường dẫn /robots.txt.
- Ví dụ chuẩn:
https://domain.com/robots.txt. - File phải nằm ở root directory (thư mục gốc), không phải thư mục con.
- File trên subdomain nào chỉ có hiệu lực với subdomain đó.
- Ví dụ:
blog.domain.com/robots.txtkhông điều khiểnwww.domain.com.
Robots.txt hoạt động như thế nào?
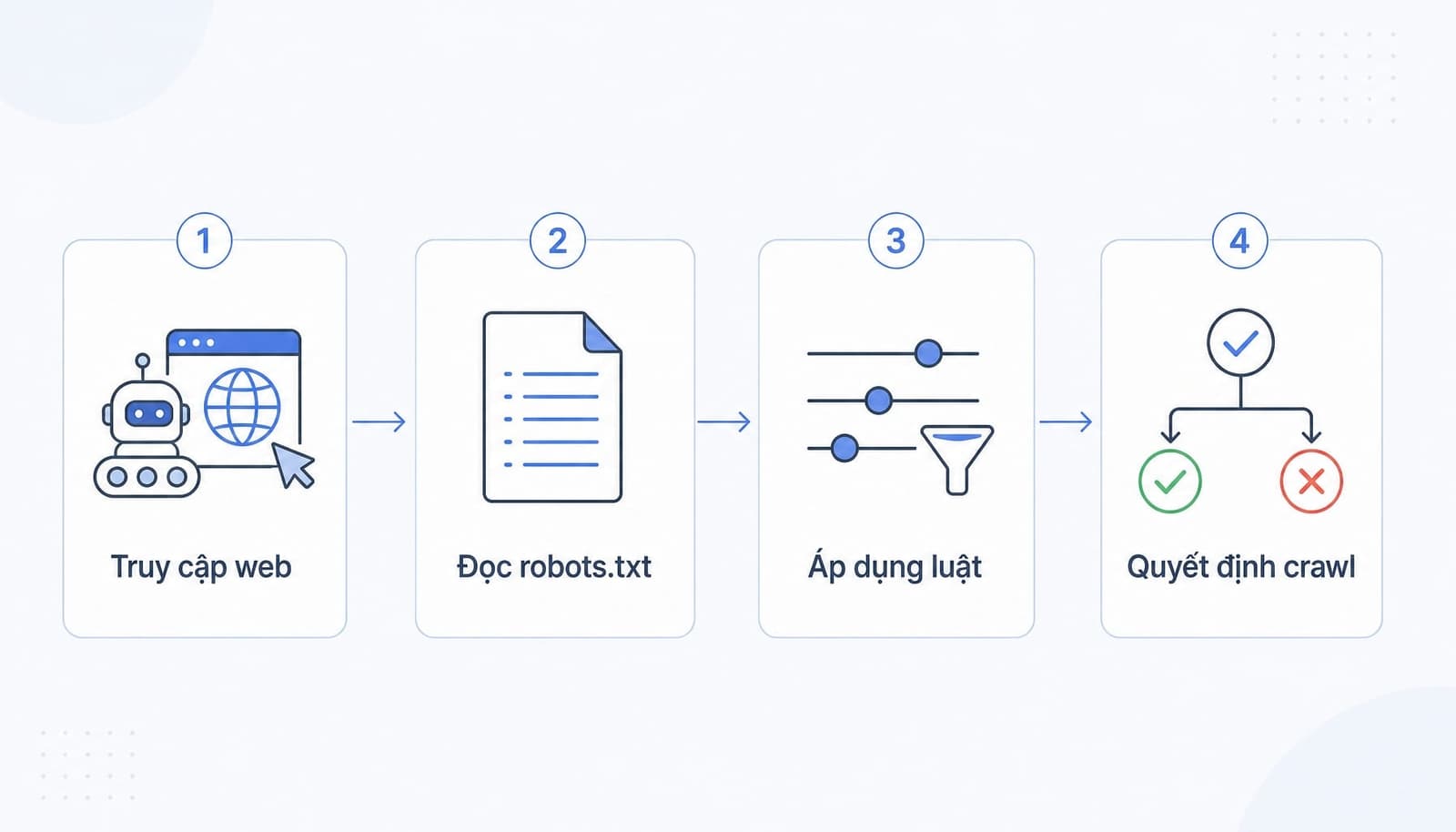
Cơ chế hoạt động khá đơn giản:
- Bot truy cập website.
- Bot tìm và đọc file robots.txt.
- Bot đối chiếu rule theo User-agent (định danh bot).
- Bot quyết định URL nào được crawl hoặc bị bỏ qua.
Một vài điểm quan trọng:
- Nếu website không có file robots.txt, bot vẫn có thể crawl bình thường.
- Bot uy tín như Googlebot thường tuân thủ chỉ dẫn.
- Bot xấu hoặc scraper có thể bỏ qua hoàn toàn file này.
- Vì file robots.txt là file public, bất kỳ ai cũng có thể xem nội dung của nó.
Chốt lại, file robots.txt là công cụ hướng dẫn crawler, không phải công cụ khóa truy cập.
Robots.txt dùng để làm gì trong SEO?
Tầm ảnh hưởng của Robots.txt chủ yếu nằm ở khả năng kiểm soát crawl, không phải ở việc ép Google bỏ index một trang.
Trong SEO, robots.txt giúp bot tránh các khu vực ít giá trị tìm kiếm hoặc không cần ưu tiên. Điều này đặc biệt hữu ích khi website có nhiều URL phát sinh từ bộ lọc, tham số, trang nội bộ hoặc môi trường test. Khi đó, bot có thể lãng phí tài nguyên vào những URL không tạo giá trị organic thay vì tập trung vào trang dịch vụ, danh mục, bài viết chuyên môn hay landing page.
Với website có quy mô lớn, đây còn là câu chuyện về crawl budget (ngân sách thu thập dữ liệu). Hiểu đơn giản, đó là lượng tài nguyên mà bot dành để quét website trong một khoảng thời gian. Nếu site có quá nhiều URL kém giá trị, bot có thể mất thời gian ở sai chỗ.
Robots.txt dùng trong SEO chủ yếu để:
- Hướng bot tránh các khu vực ít giá trị SEO.
- Giảm crawl lãng phí trên site có nhiều URL.
- Tránh crawl thư mục quản trị, khu test hoặc trang lọc.
- Hỗ trợ bot tập trung hơn vào nội dung quan trọng.
- Khai báo vị trí sitemap.xml để bot khám phá nội dung nhanh hơn.
Ví dụ thực tế dễ hiểu là website thương mại điện tử hoặc site có nhiều bộ lọc URL. Một trang danh mục có thể sinh ra hàng trăm biến thể như màu sắc, mức giá, sắp xếp. Nếu không kiểm soát, bot có thể dành phần lớn thời gian để crawl các URL gần như trùng nhau.
Khi nào nên dùng robots.txt?
Bạn nên dùng robots.txt khi cần hướng bot tránh các khu vực không cần thiết của website.
- Website có nhiều URL lọc, tham số, phân trang kém giá trị.
- Có staging site, thư mục test hoặc môi trường phát triển cần tránh crawl.
- Có các trang nội bộ như
/login/,/cart/,/search/không cần bot ưu tiên. - Muốn khai báo rõ đường dẫn sitemap.xml.
- Muốn giảm crawl lãng phí trên site lớn, nhiều nghìn URL.
Khi nào không nên lạm dụng robots.txt?
Có ba tình huống nên đặc biệt cẩn trọng:
- Không dùng robots.txt để giấu dữ liệu nhạy cảm.
- Không dùng robots.txt như công cụ chặn index tuyệt đối.
- Không block CSS hoặc JS quan trọng khiến bot render trang sai.
Nếu đội ngũ của bạn đang rà soát technical SEO tổng thể, nên kiểm tra song song robots.txt, sitemap.xml và báo cáo crawl trong Google Search Console để tránh nhìn file này một cách tách rời.
Robots.txt không làm được gì? Giới hạn quan trọng cần hiểu đúng
Hiểu lầm lớn nhất là nghĩ rằng robots.txt có thể làm một trang “biến mất” khỏi Google. Thực tế, robots.txt và noindex là hai thứ khác nhau.
Robots.txt kiểm soát việc bot có được crawl URL hay không. Trong khi đó, index là việc URL có được lưu vào chỉ mục tìm kiếm và có khả năng xuất hiện trên Google hay không. Một URL bị chặn crawl vẫn có thể bị Google biết đến nếu có liên kết từ nơi khác trỏ vào.
Điều này dẫn đến nguyên tắc rất quan trọng trong crawl vs index: Chặn bot vào không đồng nghĩa chặn URL xuất hiện tìm kiếm. Nếu muốn xử lý chuyện chặn index, bạn cần nghĩ đến meta robots hoặc x-robots-tag chứ không chỉ robots.txt.
Cũng cần nhấn mạnh thêm: robots.txt không phải lớp bảo mật. Vì file này truy cập công khai, nó không phù hợp để bảo vệ dữ liệu nội bộ, tài liệu riêng tư hay khu vực chỉ dành cho nhân sự.
Nếu chỉ nhớ một điều, bạn hãy nhớ: robots.txt chủ yếu để điều hướng crawl, còn noindex mới là tín hiệu xử lý index.
Bảng phân biệt robots.txt vs meta robots vs x-robots-tag
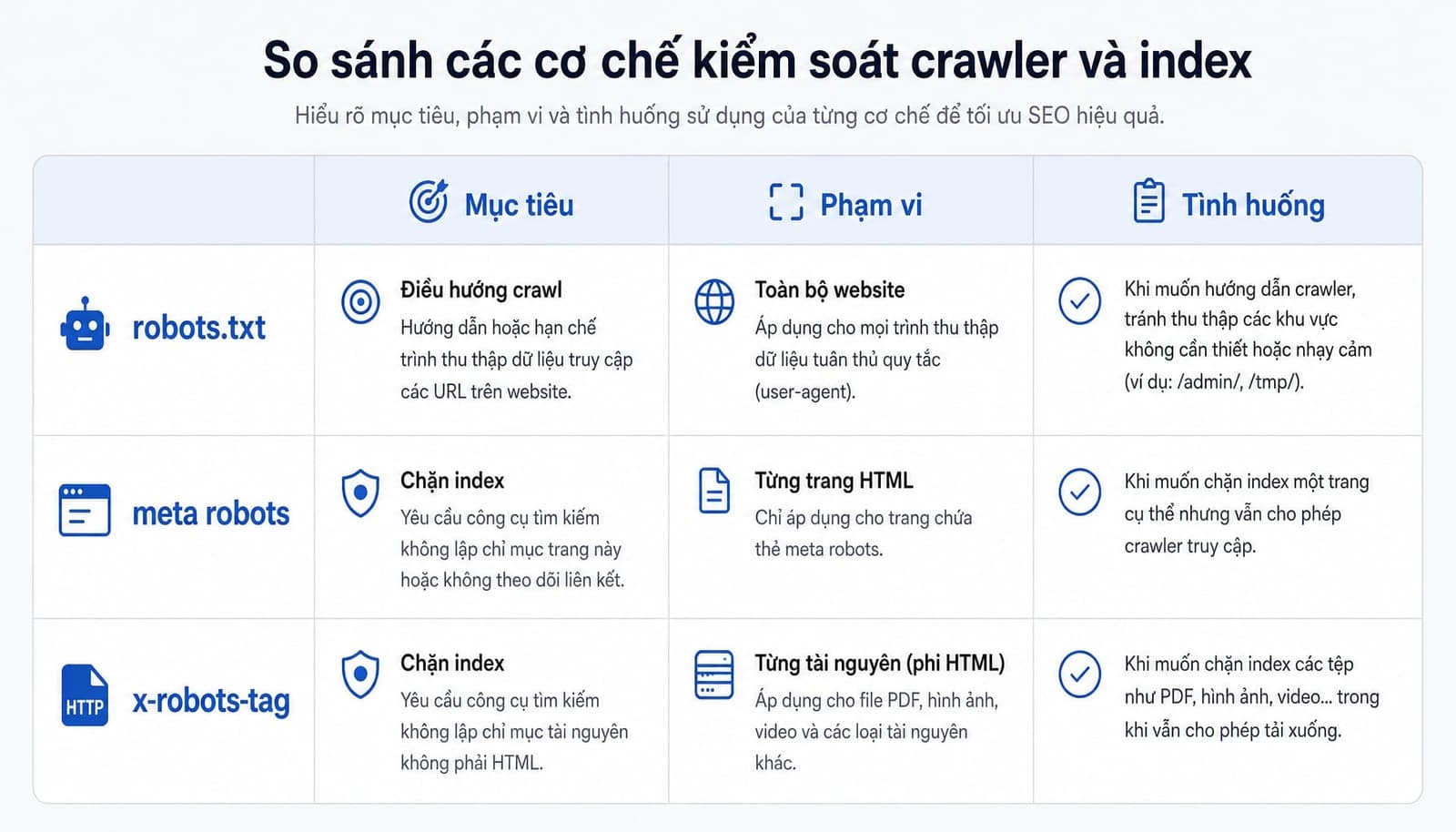
Công cụ | Dùng để làm gì? | Áp dụng ở đâu? | Phù hợp khi nào? |
|---|---|---|---|
robots.txt | Hướng dẫn bot có nên crawl hay không. | Cấp website hoặc subdomain. | Muốn bot tránh thư mục, trang lọc, khu test. |
meta robots | Hướng dẫn index/follow cho từng trang HTML. | Trong phần | Muốn trang không lên Google bằng |
x-robots-tag | Hướng dẫn index cho file không phải HTML. | HTTP header. | Muốn xử lý PDF, ảnh hoặc file khác. |
Một lưu ý quan trọng khác: Nếu bạn vừa chặn URL bằng robots.txt vừa đặt noindex trong trang đó, Google có thể không đọc được thẻ noindex vì bot không được crawl vào trang.
Quy tắc nhớ nhanh cho người không chuyên
- Muốn bot đừng vào một khu vực → Dùng robots.txt.
- Muốn trang không lên Google → Dùng
noindex - Muốn bảo mật thật sự → Dùng mật khẩu hoặc xác thực truy cập.
Cấu trúc file robots.txt cơ bản: User-agent, Disallow, Allow, Sitemap
Một file robots.txt thường gồm các rule áp dụng cho bot theo User-agent. Mỗi rule sẽ nói bot nào bị ảnh hưởng và khu vực nào được phép hoặc không được phép truy cập.
Bốn thành phần cơ bản bạn cần hiểu là:
- User-agent: Xác định bot nào đang được áp dụng rule.
- Disallow: Chỉ đường dẫn bot không nên crawl.
- Allow: Cho phép ngoại lệ trong vùng đang bị hạn chế.
- Sitemap: Khai báo vị trí sơ đồ website.
Không cần đi quá sâu vào cú pháp nâng cao để bắt đầu. Với phần lớn website phổ thông, hiểu đúng bốn directive này đã đủ để cấu hình an toàn.
Ví dụ robots.txt đơn giản
User-agent: *
Disallow: /admin/
Disallow: /search/
Allow: /
Sitemap: https://domain.com/sitemap.xml
Giải thích từng dòng:
User-agent: *→ Áp dụng cho tất cả bot.Disallow: /admin/→ Không muốn bot crawl thư mục quản trị.Disallow: /search/→ Tránh bot crawl trang tìm kiếm nội bộ.Allow: /→ Cho phép crawl các khu vực còn lại.Sitemap:https://domain.com/sitemap.xml→ Chỉ vị trí sitemap location để bot khám phá URL quan trọng.
Bạn cũng có thể tạo rule riêng cho Googlebot hoặc một bot cụ thể khác thay vì áp dụng chung cho tất cả.
Một số directive thường gây nhầm lẫn
Đây là phần dễ sai nhất khi mới cấu hình:
Disallow: /→ Chặn toàn bộ website khỏi việc crawl.Disallow:để trống → Không chặn gì cả.- Disallow directive chỉ liên quan đến crawl, không phải index.
- Allow directive thường dùng khi bạn muốn mở ngoại lệ trong một vùng bị chặn.
Noindextrong robots.txt không còn là lựa chọn nên dùng cho Google.
Trong audit thực tế, lỗi phổ biến nhất là nhầm lẫn giữa Disallow: / và Disallow:. Chỉ khác rất ít ký tự nhưng tác động hoàn toàn trái ngược.
Cách tạo và kiểm tra file robots.txt cho website
Cách tạo file robots.txt ở mức cơ bản khá đơn giản. Bạn không cần hệ thống phức tạp, chỉ cần một file .txt, đặt đúng vị trí và kiểm tra kỹ sau khi upload.
Quy trình an toàn nên đi theo các bước sau:
- Xác định mục đích cần chặn:
- Liệt kê rõ thư mục hoặc URL không cần bot crawl.
- Chỉ chặn những khu vực thực sự ít giá trị SEO.
- Soạn file bằng text editor:
- Dùng trình soạn thảo văn bản đơn giản.
- Viết rule theo từng dòng rõ ràng.
- Backup cấu hình cũ trước khi sửa:
- Nếu website đã có file robots.txt, hãy sao lưu bản hiện tại.
- Đây là bước nhỏ nhưng giúp giảm rủi ro khi cần rollback.
- Upload lên thư mục gốc:
- File phải tên chính xác là
robots.txt. - Đặt tại root directory của domain hoặc subdomain tương ứng.
- File phải tên chính xác là
- Truy cập trực tiếp để kiểm tra:
- Mở
https://domain.com/robots.txt. - Xác nhận file hiển thị đúng nội dung mong muốn.
- Mở
- Đối chiếu trong Google Search Console:
- Kiểm tra xem bot có gặp lỗi crawl hoặc URL bị block ngoài ý muốn hay không.
- Theo dõi thêm báo cáo coverage và index nếu cần.
Ví dụ file robots.txt trên website thực tế
Nếu bạn đang tìm hướng dẫn cấu hình robots.txt chuẩn Google, nguyên tắc an toàn nhất là cấu hình tối giản, rõ ràng, và chỉ thêm rule khi thực sự hiểu mục đích của từng dòng.
Cách kiểm tra website đã có robots.txt chưa
- Truy cập trực tiếp
https://domain.com/robots.txt. - Nếu thấy nội dung text hiển thị, website đã có file hoặc robots.txt ảo.
- Nếu trả về 404, có thể website chưa có file hoặc chưa đặt đúng chỗ.
Gợi ý nhanh cho WordPress và website phổ thông
- WordPress đôi khi có robots.txt dạng ảo do hệ thống sinh ra.
- Bạn vẫn cần kiểm tra bản hiển thị thực tế trên trình duyệt.
- Không nên sửa theo mẫu trên mạng nếu chưa hiểu cấu trúc URL site của mình.
- Luôn backup trước mỗi lần thay đổi.
Nếu cần rà soát nhanh toàn bộ cấu trúc crawl, bạn có thể kết hợp kiểm tra robots.txt với sitemap và dữ liệu trong Google Search Console để nhìn đúng tác động thực tế.
Mẫu robots.txt cơ bản cho các website phổ biến
Các mẫu robots.txt dưới đây chỉ mang tính tham khảo. Không nên dùng nguyên bản nếu cấu trúc URL website của bạn khác.
Mẫu robots.txt website doanh nghiệp cơ bản
User-agent: *
Disallow: /admin/
Disallow: /thank-you/
Disallow: /search/
Sitemap: https://domain.com/sitemap.xml
Mẫu này phù hợp với robots.txt website doanh nghiệp có một số khu vực quản trị, trang cảm ơn hoặc tìm kiếm nội bộ không cần bot ưu tiên crawl.
Mẫu robots.txt cho WordPress cơ bản
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://domain.com/sitemap.xml
Đây là mẫu robots.txt cho WordPress thường gặp. Mục tiêu là hạn chế bot vào khu quản trị nhưng vẫn cho phép file cần thiết hoạt động đúng.
Mẫu robots.txt cho landing page đơn giản
User-agent: *
Disallow:
Sitemap: https://domain.com/sitemap.xml
Với website chỉ có vài landing page, đôi khi không cần chặn gì cả. Khi đó, file robots.txt tối giản vẫn hữu ích để khai báo sitemap.xml rõ ràng cho bot.
Điểm quan trọng là: Mẫu robots.txt chỉ là điểm bắt đầu. Bạn cần chỉnh theo cấu trúc URL thật của website, không nên copy máy móc.
7 lỗi robots.txt phổ biến có thể làm hại SEO
Phần lớn lỗi thường gặp khi thiết lập file robots.txt không đến từ việc thiếu file, mà đến từ cấu hình nhầm. Trong technical SEO, những lỗi này có thể làm giảm crawlability và ảnh hưởng indexing gián tiếp.
- Dùng
Disallow: /trên website live: Đây là lỗi nặng nhất. Bot có thể bị chặn crawl toàn site, khiến nội dung quan trọng không được thu thập đúng. - Block nhầm thư mục chứa trang dịch vụ, sản phẩm hoặc blog: Nhiều website chặn nhầm thư mục nội dung chính sau khi đổi cấu trúc URL. Hệ quả là traffic organic giảm dần mà đội ngũ không phát hiện sớm.
- Chặn CSS hoặc JS quan trọng: Nếu bot không tải được tài nguyên render, Google có thể hiểu sai bố cục hoặc nội dung trang.
- Dùng robots.txt để che dữ liệu nhạy cảm: Đây không phải công cụ bảo mật. Vì file public, nó còn có thể vô tình “chỉ điểm” khu vực riêng tư.
- Khai báo sitemap sai URL: Nếu đường dẫn sitemap.xml sai, bot sẽ không nhận được chỉ dẫn đúng về URL quan trọng.
- Copy mẫu trên mạng mà không hiểu cấu trúc website: Một mẫu đúng với site khác chưa chắc đúng với site của bạn. Đây là nguyên nhân rất phổ biến trong audit robots.txt.
- Sửa file nhưng không test lại: Nhiều lỗi chỉ xuất hiện sau khi deploy. Nếu không kiểm tra thủ công và trong Google Search Console, rủi ro kéo dài khá lâu.
Checklist trước khi publish robots.txt:
- Có vô tình dùng
Disallow: /không? - Có block nhầm trang quan trọng không?
- Có chặn CSS, JS hoặc tài nguyên render cần thiết không?
- URL sitemap.xml đã đúng chưa?
- Đã test trực tiếp và kiểm tra lại trong Google Search Console chưa?
Ví dụ thực tiễn: Vì sao lỗi robots.txt có thể ảnh hưởng traffic và lead
Trong một lần audit robots.txt, chúng tôi gặp website vừa deploy phiên bản mới và vô tình block nhầm thư mục chứa blog chuyên môn. Về mặt giao diện, website vẫn hoạt động bình thường nên đội ngũ nội bộ không phát hiện ngay.
Vấn đề nằm ở crawlability: Bot khó tiếp cận nhóm URL đang mang phần lớn organic traffic. Sau vài tuần, lượng truy cập tự nhiên giảm dần, nhiều bài viết mất nhịp cập nhật trong chỉ mục và số lead đến từ SEO cũng yếu đi tương ứng.
Bài học ở đây khá rõ. Trong technical SEO, robots.txt là một chi tiết nhỏ nhưng có tác động lớn đến khả năng bot hiểu và truy cập website. Kiểm tra file này nên là bước bắt buộc sau mỗi lần deploy, đổi cấu trúc URL hoặc chỉnh sửa hệ thống CMS.
Câu hỏi thường gặp
Robots.txt là gì?
Robots.txt là file văn bản đặt ở thư mục gốc website, dùng để hướng dẫn bot công cụ tìm kiếm nên hoặc không nên crawl URL nào. File này kiểm soát crawl, không phải công cụ bảo mật hay chặn index tuyệt đối.
File robots.txt nằm ở đâu?
File robots.txt nằm ở thư mục gốc của website và thường truy cập qua đường dẫnhttps://domain.com/robots.txt. Với subdomain, mỗi host cần file riêng, ví dụhttps://blog.domain.com/robots.txt.
Robots.txt có chặn index trên Google không?
Không. Robots.txt chủ yếu chặn crawl, không đảm bảo chặn index. Nếu URL bị liên kết từ nơi khác, Google vẫn có thể hiển thị URL đó. Muốn chặn index, bạn hãy dùng noindex, meta robots hoặc x-robots-tag.
Robots.txt khác gì noindex?
Robots.txt hướng dẫn bot không crawl một URL hoặc thư mục, còn noindex yêu cầu công cụ tìm kiếm không đưa trang vào kết quả tìm kiếm. Muốn Google thấy noindex, trang thường cần được phép crawl.
Có cần tạo robots.txt cho mọi website không?
Không bắt buộc, nhưng nên có nếu bạn muốn kiểm soát bot, khai báo sitemap.xml hoặc tránh crawl các khu vực ít giá trị SEO. Website nhỏ có thể vẫn được Google crawl bình thường nếu không có robots.txt.
Cách kiểm tra website có robots.txt chưa?
Bạn truy cập trực tiếphttps://domain.com/robots.txt. Nếu thấy nội dung dạng text, website đã có file robots.txt. Nếu trả về 404, file có thể chưa tồn tại hoặc chưa được đặt đúng ở thư mục gốc.
Disallow: / trong robots.txt có nghĩa là gì?
Disallow: / nghĩa là yêu cầu bot không crawl toàn bộ website trong phạm vi user-agent áp dụng. Đây là lỗi nghiêm trọng nếu xuất hiện trên website live vì có thể làm Googlebot bỏ qua các trang quan trọng.
Có nên chặn bot AI bằng robots.txt không?
Có thể, nếu bạn muốn hạn chế một số AI crawler truy cập nội dung. Tuy nhiên, robots.txt dựa trên sự tuân thủ tự nguyện; bot uy tín có thể tôn trọng, còn bot xấu hoặc scraper vẫn có thể bỏ qua.
Xem thêm:
- URL parameter là gì? Cách hoạt động và lưu ý tối ưu SEO
- Negative SEO là gì? Cách nhận biết và phòng tránh hiệu quả
- Hreflang là gì? Cách triển khai chuẩn cho website đa ngôn ngữ
Kết luận
Tóm lại, robots.txt là file dùng để hướng dẫn bot nên hoặc không nên crawl khu vực nào trên website. Giá trị lớn nhất của nó nằm ở kiểm soát thu thập dữ liệu, không phải bảo mật hay chặn index tuyệt đối.
Điểm quan trọng nhất bạn cần nhớ là robots.txt không đồng nghĩa với noindex. Nếu muốn một trang không xuất hiện trên Google, bạn cần dùng đúng công cụ cho bài toán đó. Bước tiếp theo rất đơn giản: Mở domain.com/robots.txt, kiểm tra rule hiện tại, đối chiếu lại với Google Search Console và chỉ chỉnh sửa sau khi đã backup đầy đủ. Nếu website vừa thay đổi cấu trúc hoặc traffic giảm bất thường, robots.txt là một trong những file bạn nên kiểm tra đầu tiên.
.jpg&w=160&q=75)


